I envision two different ways of performing transfer learning.
One would be to use a large pre-trained model like Inception with the classification layers removed (as shown below) to produce a lower-dimensional representation of the data (can be thought of as embeddings). We visualise these embeddings in projected t-SNE and PCA space below, for a particular Ising model dataset.
inception = tf.keras.applications.inception_v3.InceptionV3(include_top=False,
weights='imagenet',
input_shape=(250, 500, 3),
pooling='max',
classes=4)
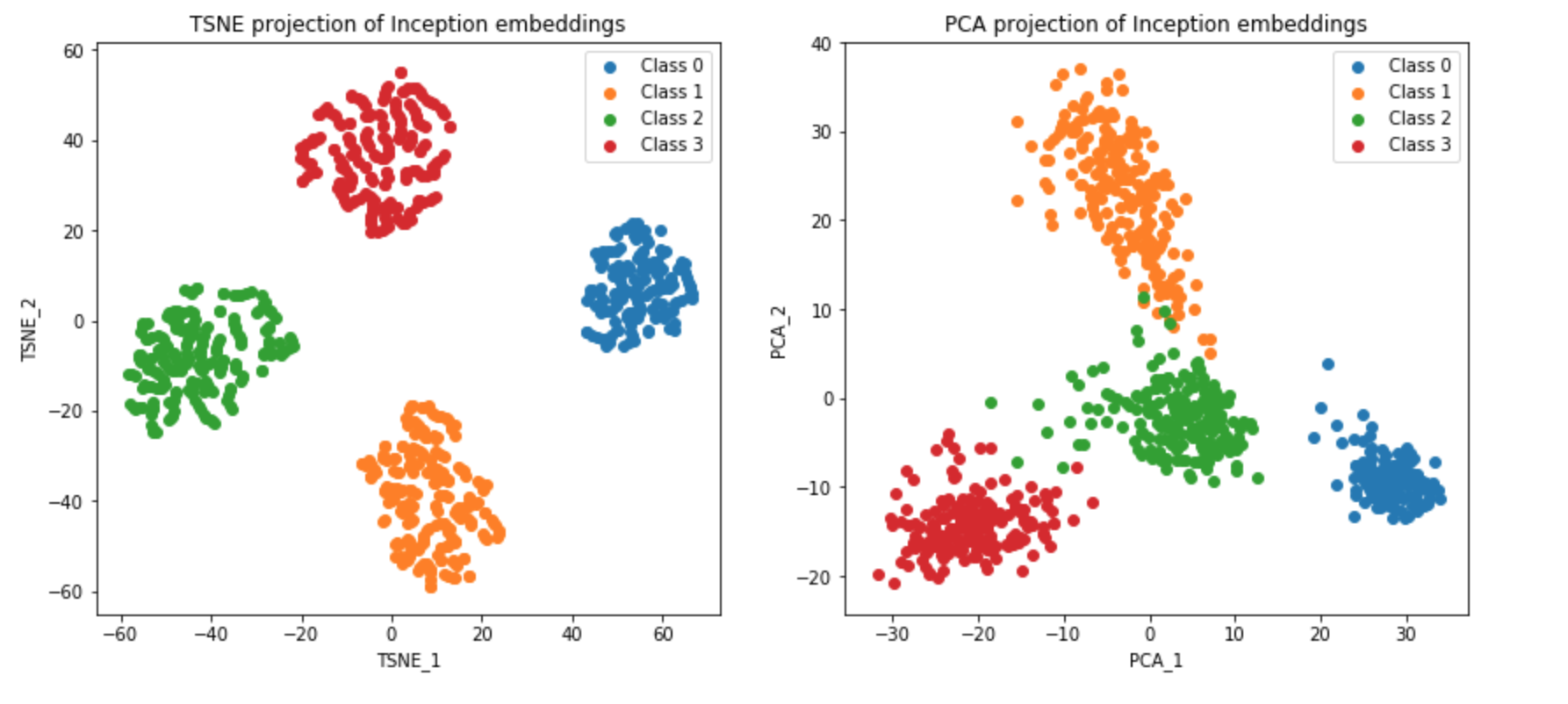
We can see that in the projected embeddings space, the classes are clearly separated. We can now train a simple classifier on these embeddings.
Another way to perform transfer learning would be to use the same Inception model as above but explicitly build classification layers on top of this to create one large model. We can then freeze the Inception part (as shown below) and train the classification layers.
inception.trainable = False
Conceptually to me, these sound like similar approaches. However, in practice, one method will outperform the other significantly, depending on which dataset I use. It is not clear to me why this is the case.